Hi everyone,
Over the last weeks, some ResNetLab collaborators (including me) conducted IPFS uptime and content routing measurements with great support from @yiannisbot. Some results can be found here, here and here. In parallel, I went ahead and built another DHT performance measurement tool for the particular use case of investigating the provide performance as it lags far behind the discovery performance.
While investigating how the whole machinery works I had an idea of how to speed things up that I would like to share with you and also would love to get feedback on.
I would call it an “Optimistic Provide” and the TL;DR would be:
For each peer, we come across during content publication, calculate the probability of an even closer one. If the likelihood is low, just store the provider record at that peer optimistically.
For the long version, I’m copying relevant parts from this repository
which includes more (but partially irrelevant) plots than I’m sharing here in this post.
Motivation
When IPFS attempts to store a provider record in the DHT it tries to find the 20 closest peers to the corresponding CID using the XOR distance.
To find these peers, IPFS sends FIND_NODES RPCs to the closest peers in its routing table and then repeats the process for the set of returned peers.
There are two termination conditions for this process:
- Termination: The 20 closest peers to the CID were queried for even closer peers but didn’t yield closer ones.
- Starvation: All peers in the network were queried (if I interpret this condition correctly)
This can lead to huge delays if some of the 20 closest peers don’t respond timely or are straight out not reachable.
The following graph shows the latency distribution of the whole provide-process for 1,269 distinct provide operations.
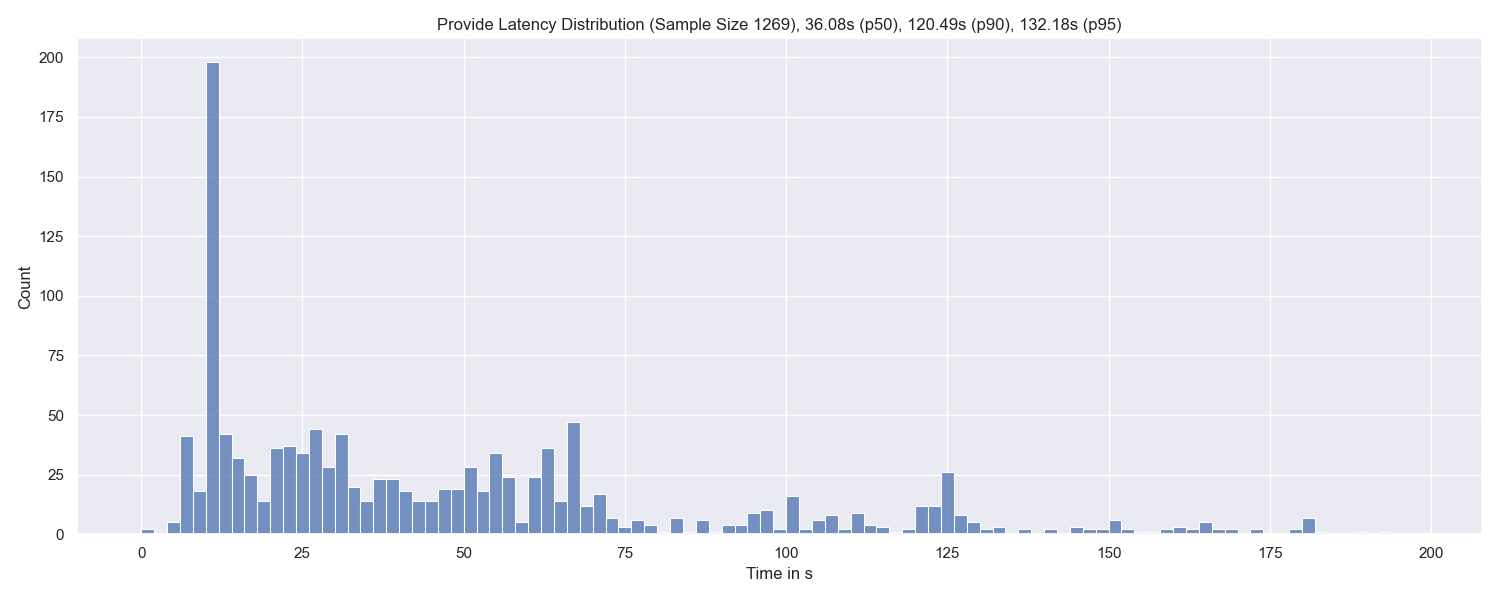
In other words, it shows the distribution of how long it takes for the kaddht.Provide(ctx, CID, true) call to return.
At the top of the graph, you can find the percentiles and total sample size. There is a huge spike at around 10s which is probably related to an exceeded context deadline - not sure though.
If we on the other hand look at how long it took to find the peers that we eventually attempted stored the provider records at, we see that it takes less than 1.6s in the vast majority of cases.
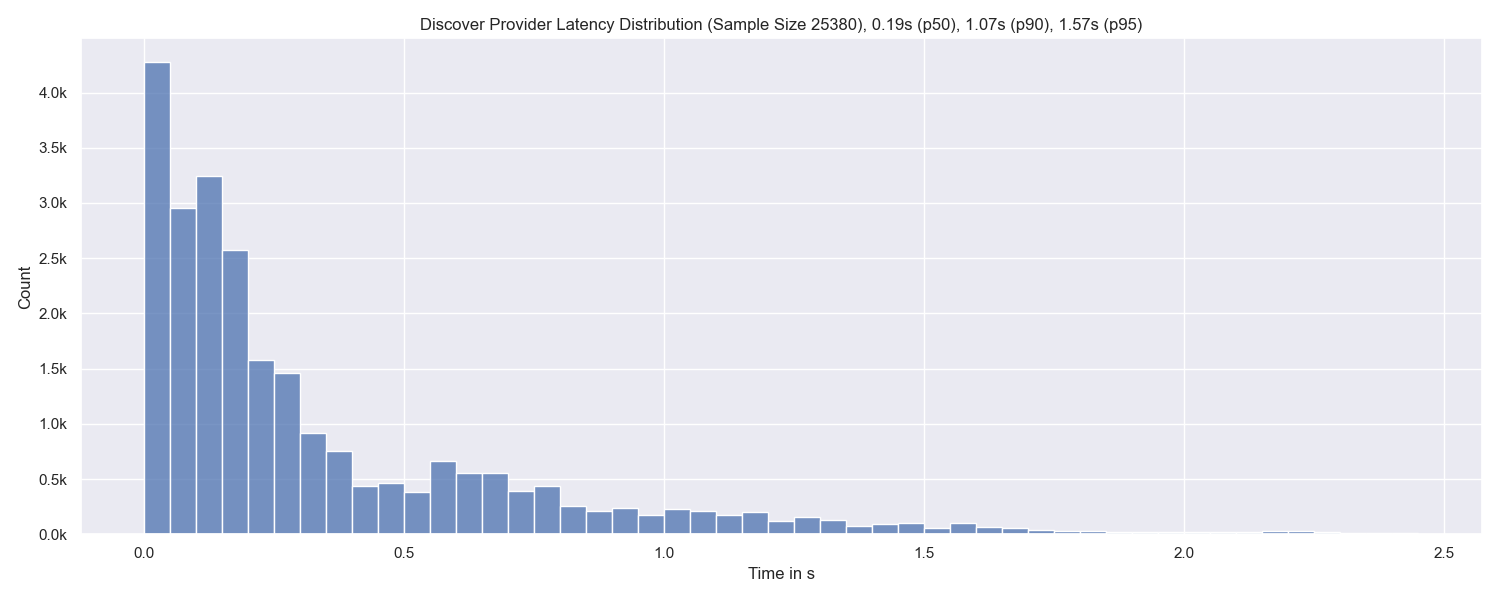
Again, sample size and percentiles are given in the figure title. The sample size corresponds to 1269 * 20 as in every Provide-run we attempt to save the provider record at 20 peers.
The same point can be made if we take a look at how many hops it took to find a peer that we eventually attempted to store the provider records at:
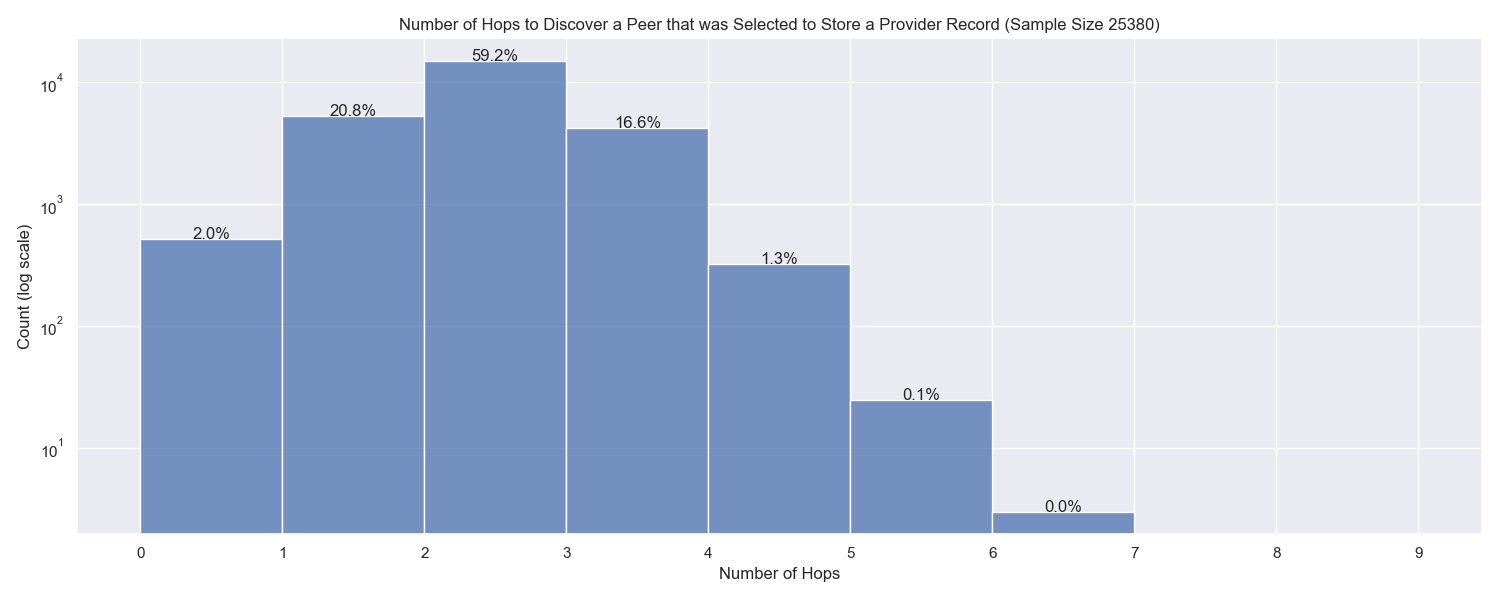
Note the log scale of the y-axis. Over 98 % of the time, an appropriate peer to store the provider record at was found in 3 hops or less.
Optimistic Provide
The discrepancy between the time the provide operations take and the time it could have taken led to the idea of just storing provider records optimistically at peers.
This would trade storing these records on potentially more than 20 peers for decreasing the time content becomes available in the network.
Further, it requires a priori information about the current network size.
Procedure
Let’s imagine we want to provide content with the CID C and start querying our closest peers.
When finding a new peer with Peer ID P we calculate the distance to the CID C and derive the expected amount of peers μ that are even closer to the CID (than the peer with peer ID P).
If we norm P and C to the range from 0 to 1 this can be calculated as:
μ = || P - C || * N
Where N is the current network size and || . || corresponds to the normed XOR distance metric.
The logic would be that if the expected value μ is less than 20 peers we store the provider record at the peer P.
This threshold could also consider standard deviation etc. and could generally be tuned to minimize falsely selected peers (peers that are not in the set of the 20 closest peers).
Example
The following graph shows the distribution of normed XOR distances of the peers that were selected to store the provider record to the CID that was provided.
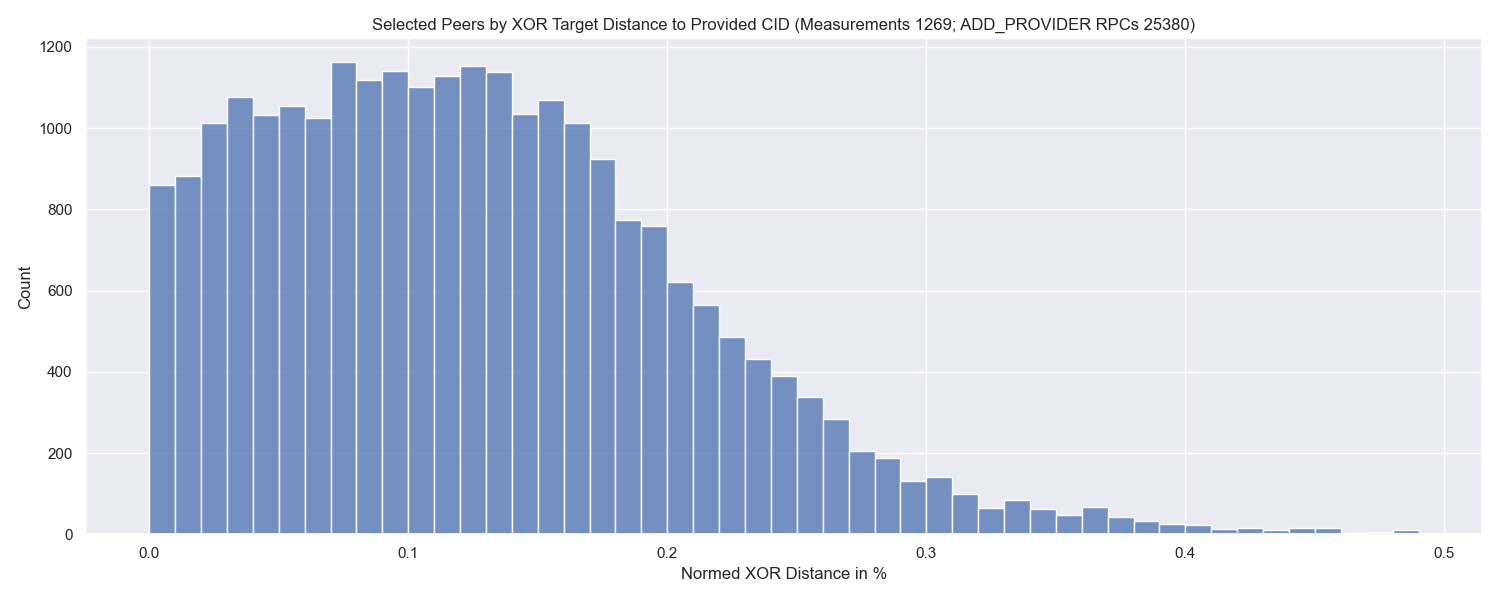
The center of mass of this distribution is roughly at 0.1 %. So if we find a peer that has a distance of || P - C || = 0.1 % while the network has a size of N = 7000 peers we would expect to find 7 peers that are closer than the one we just found.
Therefore, we would store a provider record at that peer right away.
N = 7000is a realistic assumption based on our crawls.
Network Size
Since the calculation above needs information about the current network size there is the question of how to get to that information locally on every node. I could come up with three strategies:
- Hard Coding
- Periodic full DHT crawls (was implemented in the new experimental DHT client)
- Estimation based on peer-CID proximity of previous provide operations
As said above, measurement methodology and more information are given in this GitHub - dennis-tra/optimistic-provide: A DHT measurement tool and proposal for an optimistic way to store provider records. · GitHub
repository.
Generally, I would love to hear what you think about it, if I made wrong assumptions, if I got my maths wrong, if anything else seems fishy, etc ![]()
Best,
Dennis
PS: @yiannisbot pointed me to this IPFS Content Providing Proposal. If the proposal outlined in this post proofs to be viable, I would consider it a fifth option of techniques to speed things up.