Hi everyone,
For the last two weeks, I’ve built a libp2p DHT crawler, and I’d love to discuss some of the results so far. You can find the source code here:
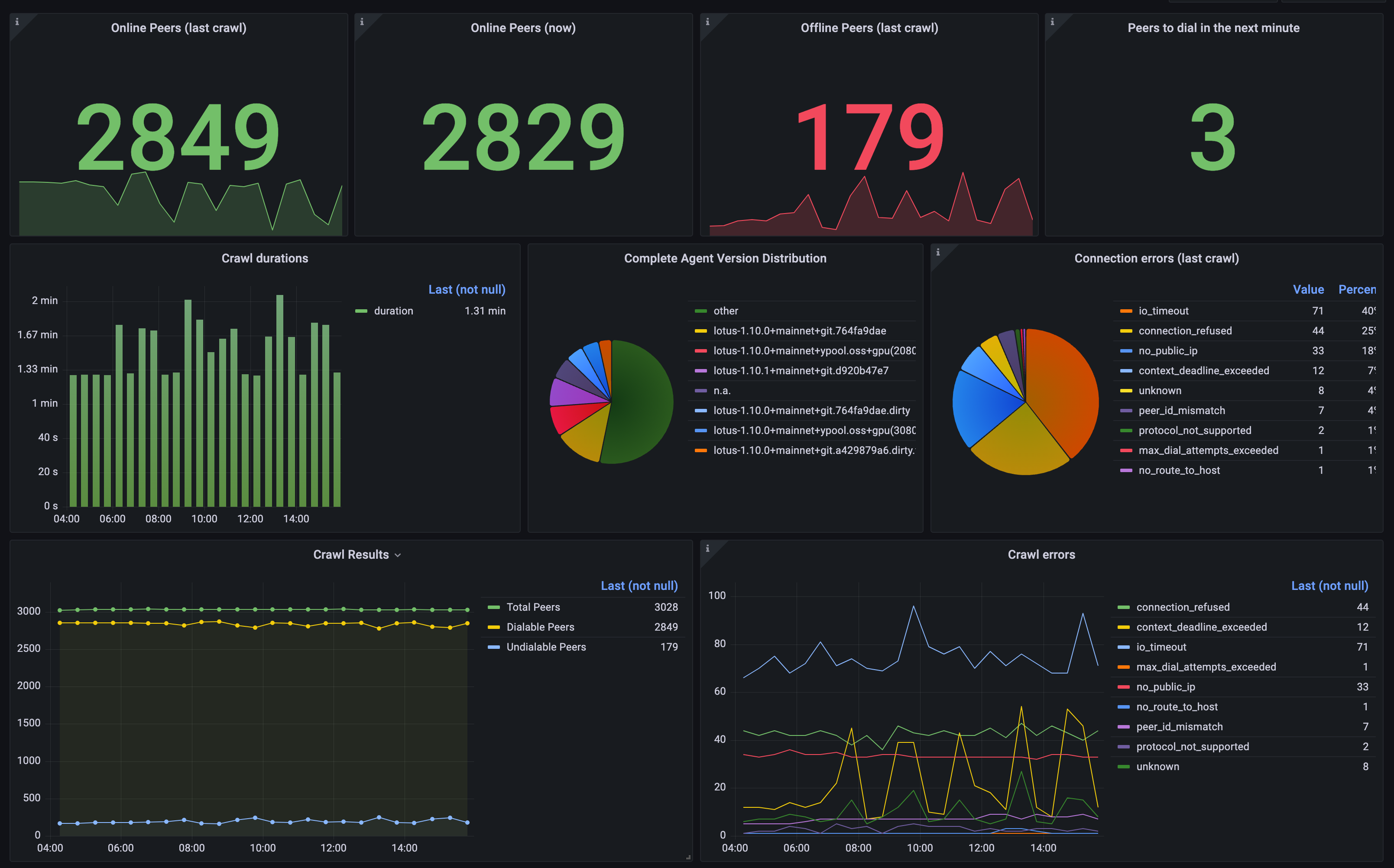
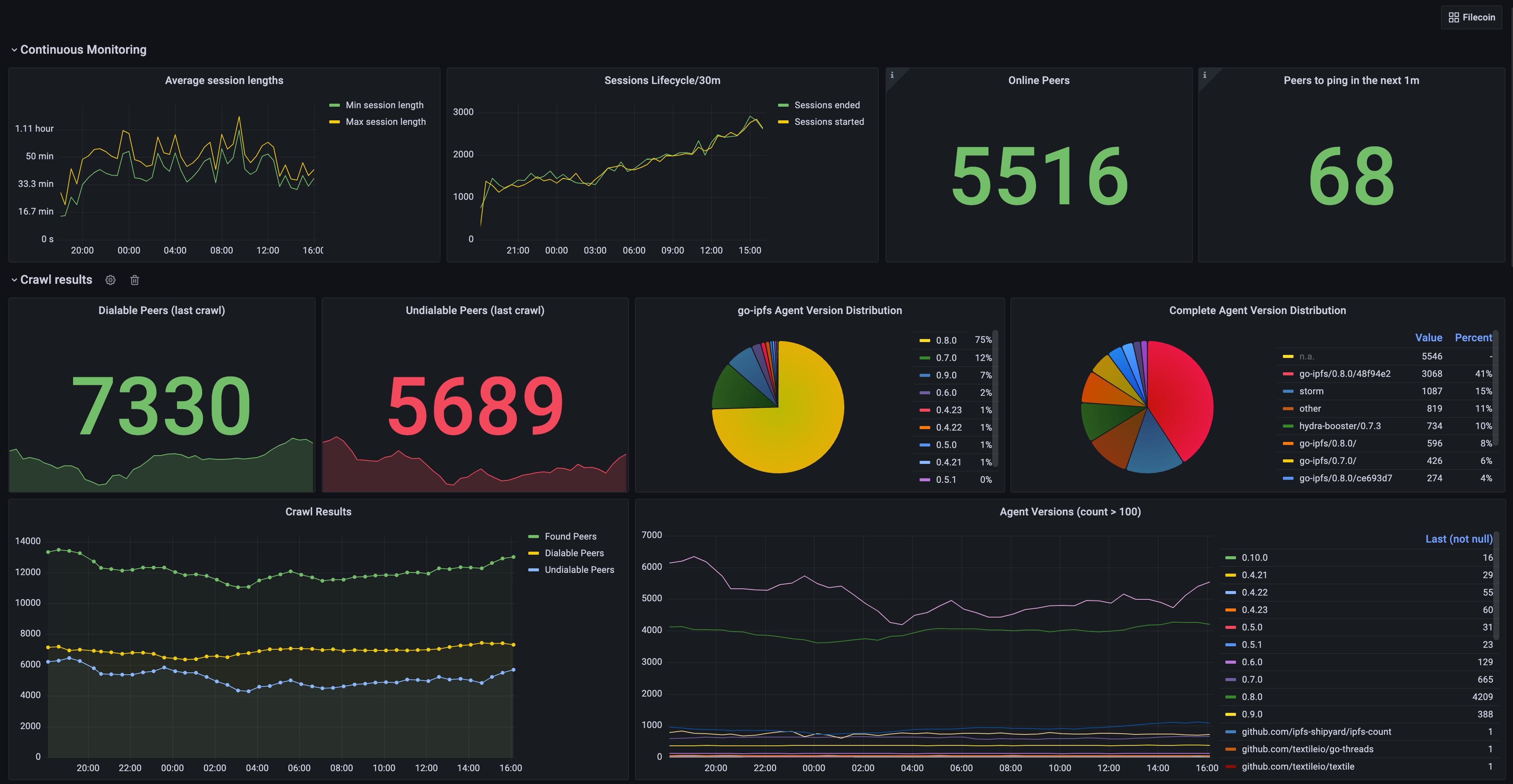
There is also a Grafana-Dashboard available here: https://nebula.dtrautwein.eu/
Just send me a PM (if that’s possible here on discourse), and I’m happy to provide login credentials to view the board. In the remainder of this post, I’m just using screenshots.
The crawler runs every 30 minutes by connecting to the standard DHT bootstrap nodes and then recursively following all entries in the k-buckets until all peers have been visited.
The crawler tracks and persists the following information:
- “Connectable” peers. This means, all peers that we could connect to AND fetch their DHT entries.
- Their supported protocols
- Their agent versions
- Their peer IDs and associated multi-addresses
- Undialable peers - peers that refused to connect or where the connection attempt timed out (timeout 60s)
- Connection error reasons
i/o timeoutconnection refusedprotocol not supportedpeer id mismatchno route to hostnetwork is unreachableno good addressescontext deadline exceededno public IP addressmax dial attempts exceededunknown
- Connection error reasons
For every peer that the crawler could connect to it creates a Session entry in the database. This information includes:
type Session struct {
// A unique id that identifies a particular session
ID int
// The peer ID in the form of Qm... or 12D3...
PeerID string
// When was the peer successfully dialed the first time
FirstSuccessfulDial time.Time
// When was the most recent successful dial
LastSuccessfulDial time.Time
// When should we try to dial the peer again
NextDialAttempt null.Time
// When did we notice that this peer is not reachable.
// This cannot be null because otherwise the unique constraint
// uq_peer_id_first_failed_dial would not work (nulls are distinct).
// An unset value corresponds to the timestamp 1970-01-01
FirstFailedDial time.Time
// The duration that this peer was online due to multiple subsequent successful dials
MinDuration null.String
// The duration from the first successful dial to the point were it was unreachable
MaxDuration null.String
// indicates whether this session is finished or not. Equivalent to check for
// 1970-01-01 in the first_failed_dial field.
Finished bool
// How many subsequent successful dials could we track
SuccessfulDials int
// When was this session instance updated the last time
UpdatedAt time.Time
// When was this session instance created
CreatedAt time.Time
}
Then there is a second mode of the crawler which I called monitor-mode. In this mode nebula fetches every 10 seconds all sessions from the database that are due to be dialed in the next 10 seconds (based on the NextDialAttempt timestamp) or overdue. It attempts to dial all peers using the saved multi-addresses and then updates their session instances accordingly if they’re dialable or not.
The dial interval increases the longer the session is. That’s the SQL logic:
next_dial_attempt =
CASE
WHEN 1.1 * (NOW() - sessions.first_successful_dial) < '30s'::interval THEN
NOW() + '30s'::interval
WHEN 1.1 * (NOW() - sessions.first_successful_dial) > '40m'::interval THEN
NOW() + '40m'::interval
ELSE
NOW() + 1.1 * (NOW() - sessions.first_successful_dial)
END;
(This is not the actual SQL statement which can be found here - it should just demonstrate the logic).
So 30s after the crawler connected the first time to a peer it tries to dial it again. If that succeeds it tries again after 33s, then after 36s, and so on…
Now as I’m writing this, this sounds quite often - what are your thoughts on the interval?
It is capped at 40m because the crawler runs every 30m and the peer should be found in the crawl (which takes a couple of minutes) anyways. If the crawl didn’t find the peer, the monitoring task will try to reach it again. At this point I’m thinking - if it’s not found in the DHT: should it then still be counted online even if the peer is dialable?
Here are some other configuration settings of the crawler that I would love to get feedback on:
- Dial timeout: 60s
- Protocols:
/ipfs/kad/1.0.0,/ipfs/kad/2.0.0- I saw 2.0.0 somewhere but don’t know if it’s necessary
- (The crawler also works with
/fil/kad/testnetnet/kad/1.0.0)
- I’m using
network.WithForceDirectDialto prevent dial backoffs and handle them myself. - The crawler does not retry connecting to peers, the monitoring process does. Three retries with
sleepDuration := time.Duration(float64(5*(i+1)) * float64(time.Second))whereiis the retry - It filters multi addresses that pass
manet.IsPrivateAddr(maddr)- is this actually necessary? I’ve seen some logic around choosing the best address.
Now some numbers:
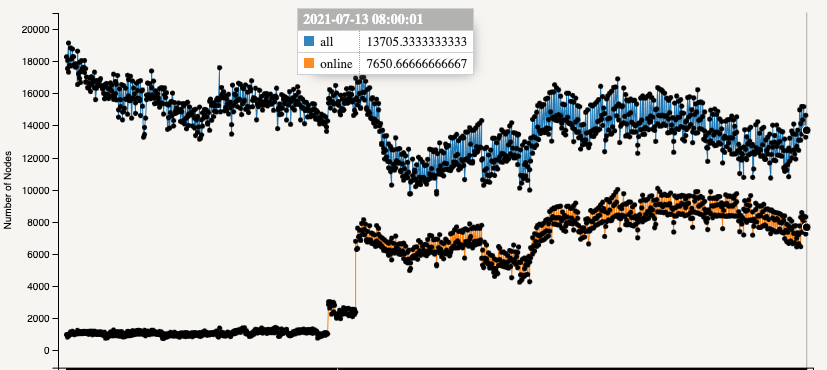
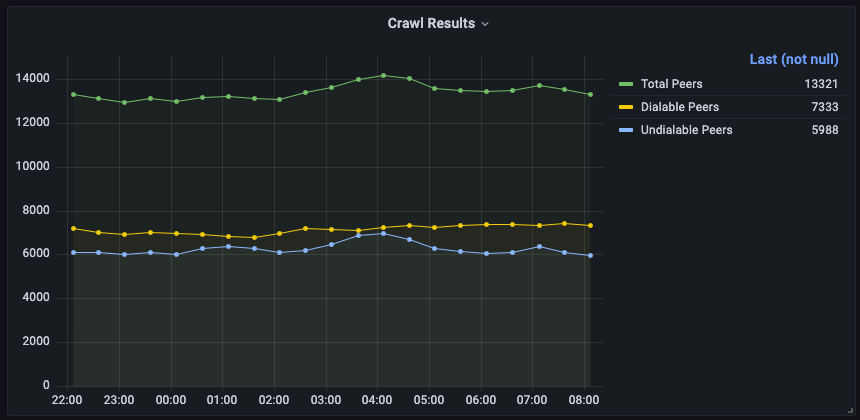
- A crawl takes roughly 5 minutes. I can get the crawl down to 2 minutes if I decrease the connection timeouts to 10s.
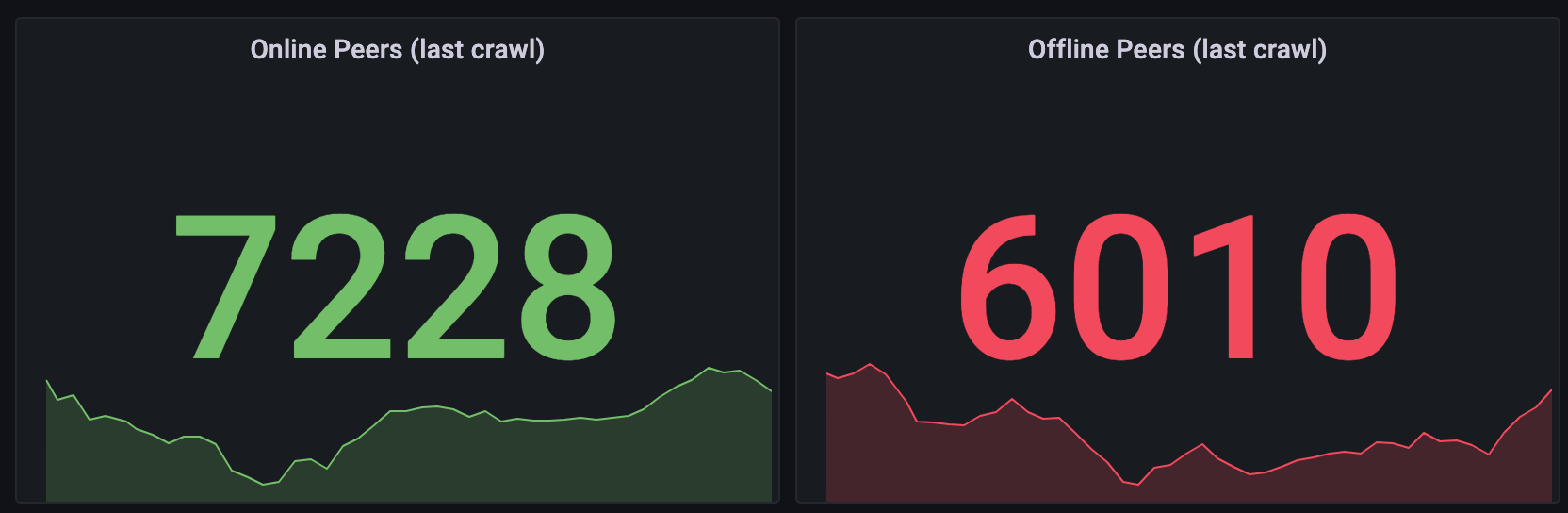
Crawled peers 2021-07-07 16:30 CEST
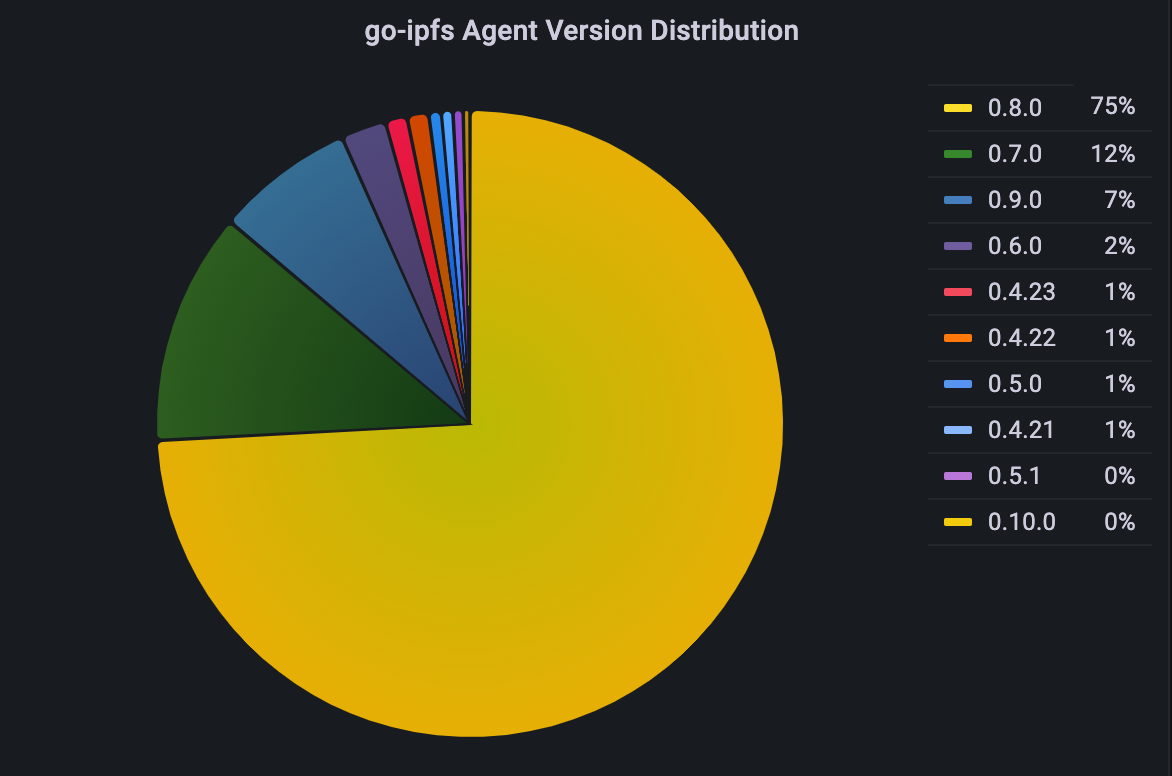
Agent version distribution (combination of all pre releases + builds)
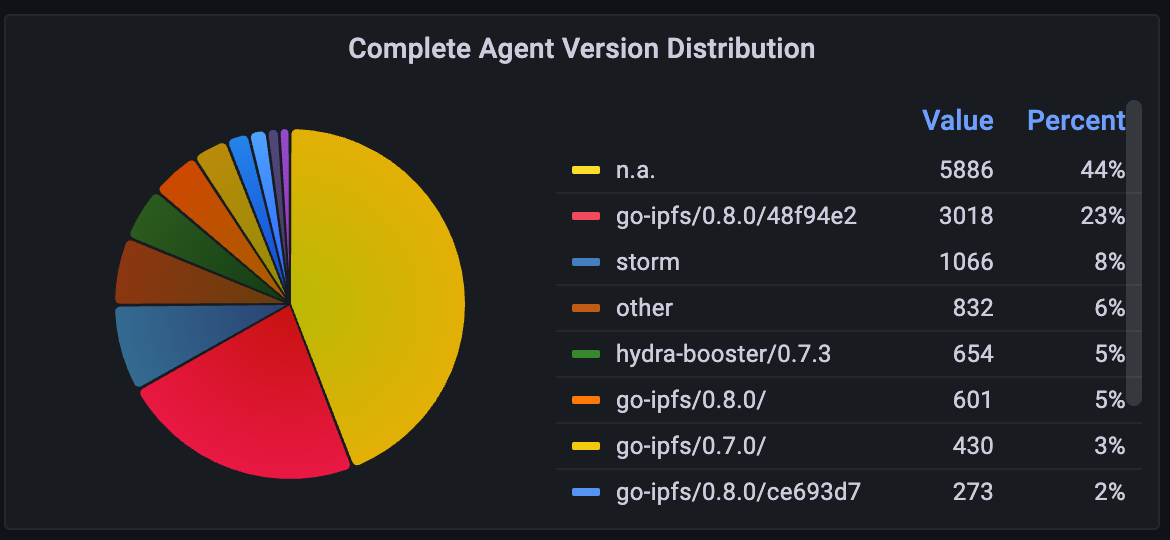
Agent version distribution II (separate prereleases + builds)
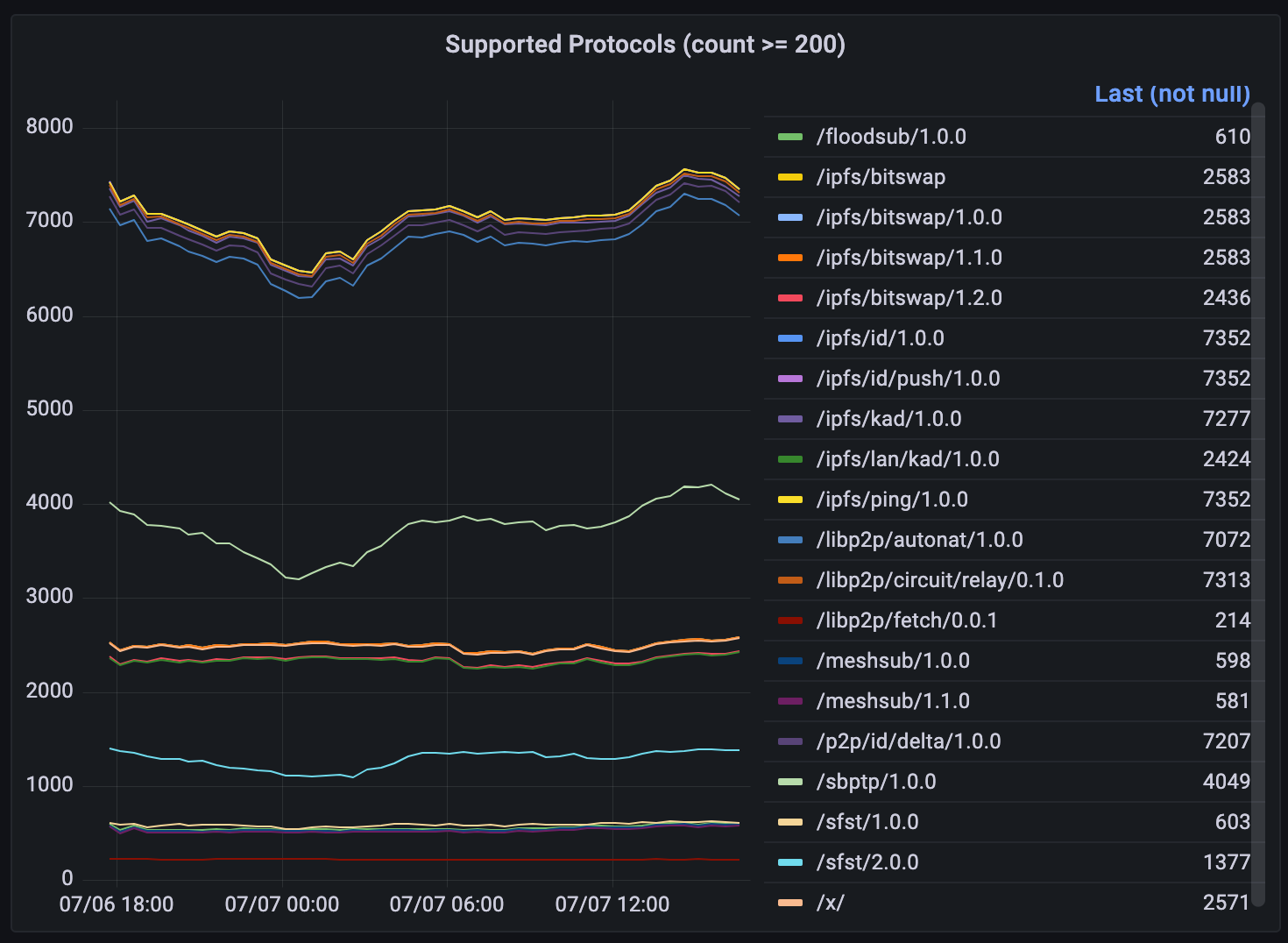
Supported Protocols where more than 200 nodes supported each protocol. There are many more protocols were there less than 200 nodes supporting each.
Connection errors of the last crawl (not “Dial” as it’s in the title of the panel):
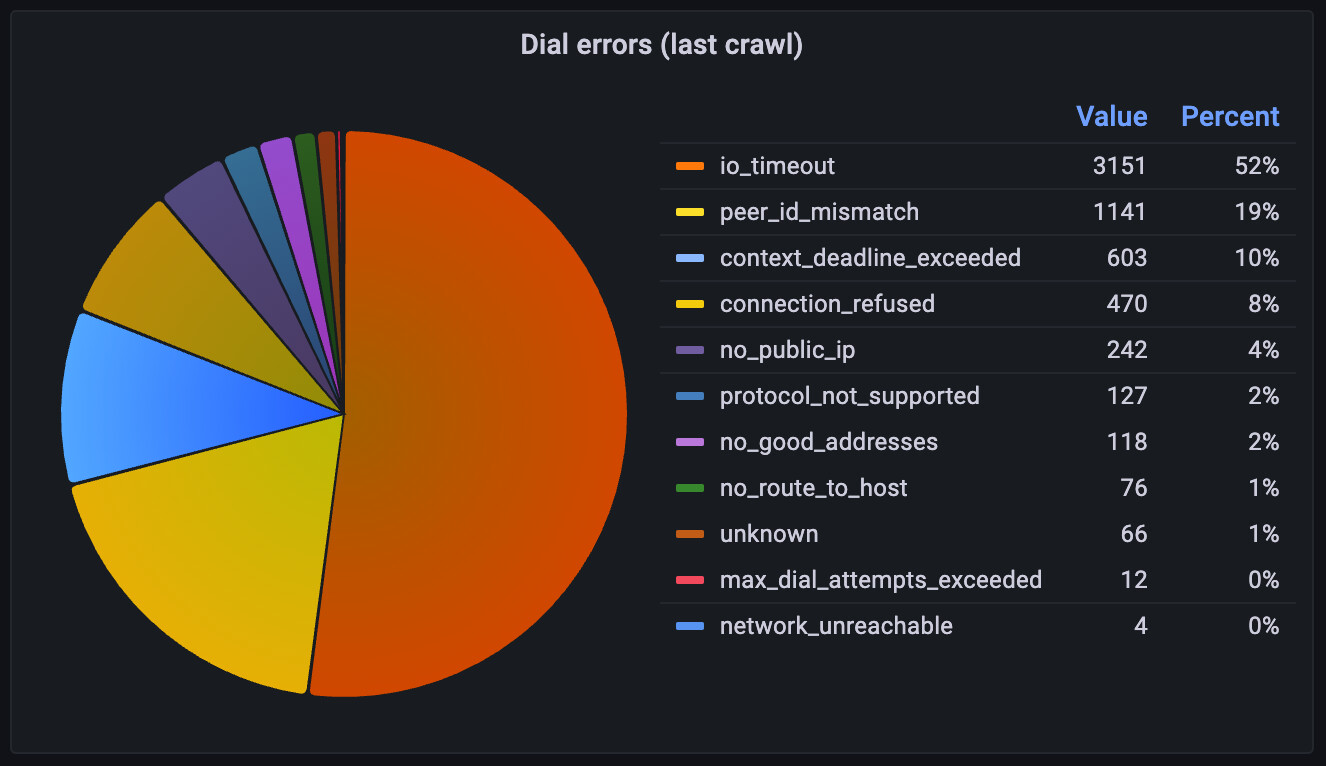
Questions:
-
I’m using a single libp2p host to crawl many peers in parallel. Similarly, the monitoring process also only uses a single host. Is there an internal limit in parallel dials that slows down the crawl and could be circumvented by instantiating multiple libp2p hosts?
-
As can be seen in the complete agent version distribution there are 44% of nodes that don’t have an agent version. The logic is basically
if err := host.Connect(ctx, peer); err != nil { return err } agent, err := host.Peerstore().Get(peer.ID, "AgentVersion") ...Could it be that the identity exchange hasn’t finished after the
Connectcall has returned? I saw that there is a channel blocking the return statement until the identity has been determined<-h.ids.IdentifyWait(c)inbasic_host.go:780but the comment above this line indicates that it’s not guaranteed:// TODO: Consider removing this? On one hand, it's nice because we can // assume that things like the agent version are usually set when this // returns. On the other hand, we don't _really_ need to wait for this. // // This is mostly here to preserve existing behavior.I’m not sure due to the word usually.
-
I’ve heard that there are 10 hydra-boosters with 100 heads each, so the crawler should find 1000 peers with the
hydra-booster/x.y.zagent version - but it’s only finding 654. Do you have an idea why? -
The monitoring process receives a lot of
connection refusederrors. This leads to a single node having many session instances in the database where the end of the previous is just a minute (or so) before the beginning of the next session. Could this be due to the frequent connection attempts? At which level could the connection be blocked - firewall, OS, libp2p? Here is an example of such a peer that responds to many connection attempts/dials and then the dial fails intermittently (despite retries).id | peer_id | first_successful_dial | last_successful_dial | next_dial_attempt | first_failed_dial | min_duration | max_duration | finished | successful_dials | updated_at | created_at --------+------------------------------------------------------+-------------------------------+-------------------------------+-------------------+-------------------------------+-----------------+-----------------+----------+------------------+-------------------------------+------------------------------- 543353 | 12D3KooWBMLEz6H1rvwfUkbAZ8oFKf6Mc9cjXH4HYYouDLQQ5dnE | 2021-07-07 15:42:41.910688+02 | 2021-07-07 15:43:02.02431+02 | | 2021-07-07 15:44:46.384017+02 | 00:00:20.113622 | 00:02:19.475972 | t | 3 | 2021-07-07 15:45:01.38666+02 | 2021-07-07 15:42:41.910688+02 542483 | 12D3KooWBMLEz6H1rvwfUkbAZ8oFKf6Mc9cjXH4HYYouDLQQ5dnE | 2021-07-07 15:37:31.67989+02 | 2021-07-07 15:39:10.85505+02 | | 2021-07-07 15:42:05.621077+02 | 00:01:39.17516 | 00:04:48.942734 | t | 5 | 2021-07-07 15:42:20.622624+02 | 2021-07-07 15:37:31.67989+02 536184 | 12D3KooWBMLEz6H1rvwfUkbAZ8oFKf6Mc9cjXH4HYYouDLQQ5dnE | 2021-07-07 15:31:20.973472+02 | 2021-07-07 15:33:25.823083+02 | | 2021-07-07 15:36:54.191171+02 | 00:02:04.849611 | 00:05:48.220279 | t | 4 | 2021-07-07 15:37:09.193751+02 | 2021-07-07 15:31:20.973472+02 509114 | 12D3KooWBMLEz6H1rvwfUkbAZ8oFKf6Mc9cjXH4HYYouDLQQ5dnE | 2021-07-07 14:17:19.863394+02 | 2021-07-07 14:46:55.404861+02 | | 2021-07-07 15:02:16.39978+02 | 00:29:35.541467 | 00:44:56.536386 | t | 9 | 2021-07-07 15:02:16.39978+02 | 2021-07-07 14:17:19.863394+02 508304 | 12D3KooWBMLEz6H1rvwfUkbAZ8oFKf6Mc9cjXH4HYYouDLQQ5dnE | 2021-07-07 14:08:07.162411+02 | 2021-07-07 14:11:38.02465+02 | | 2021-07-07 14:16:43.204443+02 | 00:03:30.862239 | 00:08:51.044115 | t | 6 | 2021-07-07 14:16:58.206526+02 | 2021-07-07 14:08:07.162411+02 503840 | 12D3KooWBMLEz6H1rvwfUkbAZ8oFKf6Mc9cjXH4HYYouDLQQ5dnE | 2021-07-07 14:02:05.212238+02 | 2021-07-07 14:04:07.819932+02 | | 2021-07-07 14:07:30.95417+02 | 00:02:02.607694 | 00:05:40.744301 | t | 4 | 2021-07-07 14:07:45.956539+02 | 2021-07-07 14:02:05.212238+02 473914 | 12D3KooWBMLEz6H1rvwfUkbAZ8oFKf6Mc9cjXH4HYYouDLQQ5dnE | 2021-07-07 12:36:34.043855+02 | 2021-07-07 13:30:22.003058+02 | | 2021-07-07 13:32:11.849455+02 | 00:53:47.959203 | 00:55:37.8056 | t | 10 | 2021-07-07 13:32:11.849455+02 | 2021-07-07 12:36:34.043855+02 473032 | 12D3KooWBMLEz6H1rvwfUkbAZ8oFKf6Mc9cjXH4HYYouDLQQ5dnE | 2021-07-07 12:34:35.546656+02 | 2021-07-07 12:34:35.546656+02 | | 2021-07-07 12:35:57.802342+02 | 00:00:00 | 00:01:37.256853 | t | 1 | 2021-07-07 12:36:12.803509+02 | 2021-07-07 12:34:35.546656+02 448752 | 12D3KooWBMLEz6H1rvwfUkbAZ8oFKf6Mc9cjXH4HYYouDLQQ5dnE | 2021-07-07 11:32:19.236026+02 | 2021-07-07 12:02:42.760365+02 | | 2021-07-07 12:33:49.411125+02 | 00:30:23.524339 | 01:01:30.175099 | t | 8 | 2021-07-07 12:33:49.411125+02 | 2021-07-07 11:32:19.236026+02 ... -
The monitoring process also receives a significant amount of peer ID mismatch errors. Could this be due to restart of libp2p hosts that have the same address but now a newly generated peer ID?
I hope you find these numbers interesting and can help me out with my questions.
Cheers,
Dennis