We recently added support for lookups over disjoint paths based on the extension research paper S/Kademlia [1] to the Rust libp2p Kademlia implementation. I have come across similar efforts in the Golang and JavaScript implementations [2] and thus thought it might be helpful to share our approach.
Notion of disjoint paths
The extension paper S-Kademlia includes a proposal for lookups over disjoint paths. Within vanilla Kademlia, queries keep track of the closest nodes in a single bucket. Any adversary along the query path can thus influence all future steps, in case they can come up with the next-closest (not overall closest) hops. S/Kademlia tries to solve the attack above by querying over disjoint paths using multiple buckets.
See S/Kademlia [1] section 4.4.
Implementation details
Below I will expand on some of the challenges we faced as well as implementation specific choices we made.
Configuration
Requiring Kademlia queries to use disjoint paths is set via a single boolean flag. There is no option to configure number of disjoint paths, but instead the amount of configured query parallelism is used as the number of disjoint paths to use. This reduces the configuration surface and aligns with the S/Kademlia paper [1].
Initial set of peers
The S/Kademlia paper [1] suggests to take the k closest peers and split them by d, initializing each disjoint paths with a subset.
The initiator starts a lookup by taking the k closest nodes to the destination key from his local routing table and distributes them into d independent lookup buckets.
Say the amount of disjoint paths d is 4. With k equal to 20 each disjoint path would get 5 peers. Further lets say that the first path only needs 1 out of those 5 nodes as the first peer the path queries returns way closer peers than the remaining 4. Now these 4 peers will never be used. Say that the second path got unlucky and none of its 5 peers are online or return anything closer. The second path could really use those 4 peers unused by the first path.
Instead of splitting the k closest peers into subsets for each disjoint path, the Rust implementation has each path choose from a joined pool on demand. In the case above the first path would choose the closest peer out of the shared pool and, as that peer returns way closer peers, never picks a peer from the pool again. Any other query path can now pick more than 5 peers from the pool, helping them succeed and thus upholding the multi-path property of the query.
See this comment for the initial discussion.
Keeping the paths disjoint
According to the S/Kademlia paper [1] a path is not allowed to contact a peer if another path has previously contacted that same peer. This constraint upholds the disjoint paths property.
The lookups are independent, except the important fact, that each node is only used once during the whole lookup process to ensure that the resulting paths are really disjoint
We made a slight modification to this constraint while still upholding the disjoint paths property. Say both the first and the second path learned of the existence of node A. The first path queries node A. Node A responds with 20 closer peers. Now the second path would like to query node A as well. Instead of dropping the request we inform the second path whether the query to node A by the first path was successful or not. We do not pass the 20 closer nodes returned by node A to the second path as that would violate the disjoint paths property by allowing node A to influence two query paths. With this slight change the second path can include node A in its final result.
For further details and multiple examples see the following discussion
Results
In order to test the implementation and compare its performance with the vanilla query approach I wrote a Prometheus exporter which explores a given libp2p DHT and exposes metrics as time-series to a Prometheus server. The code of the exporter is on Github GitHub - mxinden/kademlia-exporter: Libp2p Kademlia Exporter exposing Prometheus metrics · GitHub and a Grafana server visualizing the collected data via various dashboards is online at kademlia-exporter.max-inden.de/.
Note: Among other DHTs this exporter also explores the IPFS DHT. My implementation is still facing issues connecting to Golang Kademlia clients via Rust. Thus the collected data is not representative.
The exporter does a random FIND_NODE query every second. Using disjoint paths instead of the vanilla query approach seems to have no significant impact on the Kusama Kademlia DHT (~800 nodes).
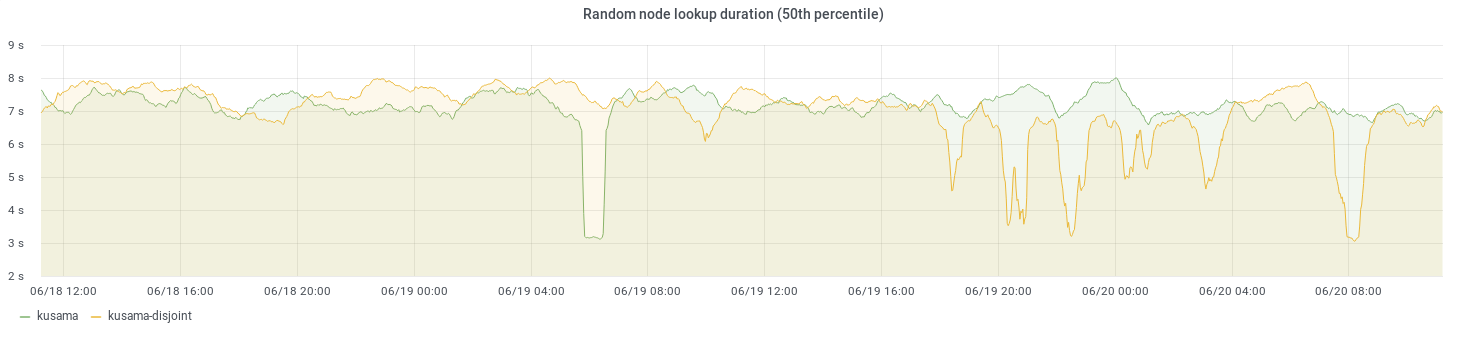
The graph below shows the amount of successful requests it takes for the above mentioned periodic random FIND_NODE query to succeed. While the disjoint-paths strategy needs more queries at any given point in time, we feel like the values are similar enough to justify the increased security guarantees.
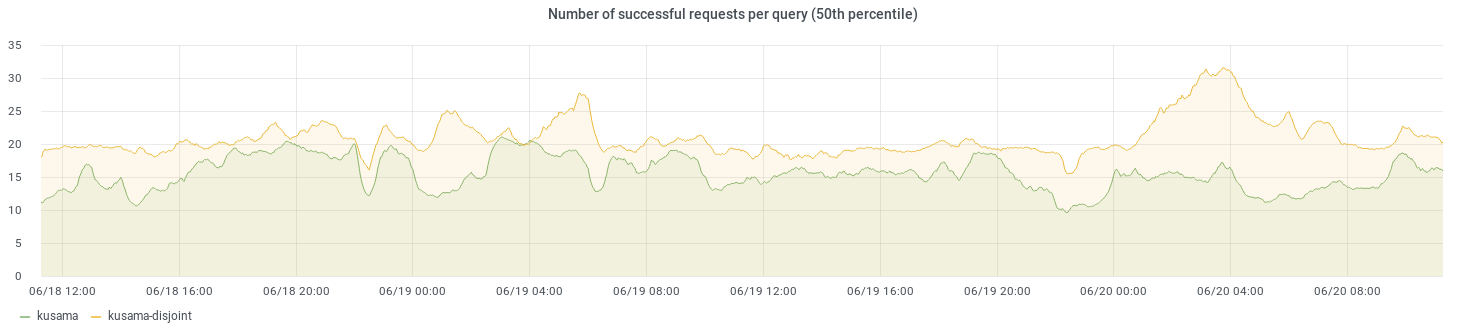
All data is publicly available at kademlia-exporter.max-inden.de/.
Future steps
-
infinity0 has made an intriguing proposal to reduce the disjoint-paths approach to a max-flow-min-cost problem. As you can see by the many discussions in the feature pull request we have faced many edge-cases which we hope to resolve with infinity0’s proposal. A detailed write-up of the proposal can be found on https://forum.web3.foundation/t/s-kademlia-and-max-flow-min-cost/375.
-
The S/Kademlia [1] section 4.2 introduces the concept of sibling lists. Having nodes be aware of their direct neighborhood should improve disjoint-paths queries as queries can more easily find the same set of closest peers via disjoint paths.
As always, happy for any comments, suggestions or concerns.
[1] Baumgart, Ingmar, and Sebastian Mies. “S/kademlia: A practicable approach towards secure key-based routing.” 2007 International Conference on Parallel and Distributed Systems. IEEE, 2007.
[2] Disjoint Path Lookups · Issue #146 · libp2p/go-libp2p-kad-dht · GitHub, DHT improvement ideas · Issue #21 · libp2p/notes · GitHub, https://github.com/libp2p/js-libp2p-kad-dht/pull/39, https://github.com/libp2p/go-libp2p-kad-dht/pull/204, Query logic closely match Kademlia paper by aschmahmann · Pull Request #436 · libp2p/go-libp2p-kad-dht · GitHub, Proposed DHTv2 Changes by aschmahmann · Pull Request #473 · libp2p/go-libp2p-kad-dht · GitHub, Remove disjoint queries by aarshkshah1992 · Pull Request #503 · libp2p/go-libp2p-kad-dht · GitHub